Note
Go to the end to download the full example code.
The Pretty Good and Pretty Bad Measurements¶
In this tutorial, we will explore the “pretty good measurement” (PGM) and its novel counterpart, the “pretty bad measurement” (PBM). The PGM, also known as the square-root measurement, is a widely used measurement for quantum state discrimination [1][2]. The PBM, in contrast, was recently introduced by McIrvin et. al. [3]. Both these measurements provide elegant, easy-to-construct tools for two opposing goals in quantum information: state discrimination and state exclusion. PGM is useful for the former while PBM is of use for the latter.
We will verify their core properties and replicate some of the key numerical
results and figures from the paper using |toqito⟩.
Background: Discrimination vs. Exclusion¶
Bob wins the standard quantum state discrimination task, if he successfully guesses the state sent by Alice. Alice is sending Bob a quantum state \(\rho_i\) chosen from an ensemble \(\{(p_i, \rho_i)\}_{i=1}^k\) known to Bob. Bob’s goal is to perform a measurement that maximizes his probability of correctly guessing the index \(i\). The best possible probability, \(P_{\text{Best}}\), is the maximum success probability achievable over all possible measurements (POVMs) \(\{M_i\}\).
However, finding \(P_{\text{Best}}\) is often computationally very hard. The “pretty good measurement” (PGM) is a well-established heuristic for this task. Its measurement operators \(G_i\) are constructed from the ensemble as:
The success probability when using the PGM is given by the standard Born rule, averaged over the ensemble:
The state exclusion task is the opposite: Bob wins if he correctly guesses a state that Alice did not send. This is equivalent to minimizing the probability of correctly guessing the state Alice did send. This minimum achievable success probability is denoted \(P_{\text{Worst}}\):
The “pretty bad measurement” (PBM) is a heuristic designed to approximate this worst-case performance. The PBM is elegantly defined in terms of the PGM operators \(G_i\). In the formula below, \(k\) is the number of states in the ensemble, and \(\mathbb{I}\) is the identity operator with the same dimensions as the states:
The success probability for discrimination when using the PBM is, analogously:
A key result from McIrvin et.al [3] is the tight relationship between the success probabilities of these two measurements:
This implies a performance hierarchy against the optimal probabilities and the blind guessing probability (\(1/k\)):
We will verify this hierarchy with a concrete example.
Numerical Example: The Trine States¶
Figure 3 from McIrvin et.al [3] analyzes the performance of these measurements for the three trine states with a uniform prior probability. The trine states are a classic example of a set that is antidistinguishable but not distinguishable, a property demonstrated in the Quantum state exclusion tutorial.
Our plan is to:
Generate the trine states and assume uniform prior probabilities.
Compute the optimal win/loss probabilities, \(P_{\text{Best}}\) and \(P_{\text{Worst}}\), using
|toqito⟩’s SDP solvers.Construct the PGM and PBM measurement operators.
Calculate the success probabilities \(P_{\text{PGM}}\) and \(P_{\text{PBM}}\).
Print and compare all values, verifying the performance hierarchy and the relationship between \(P_{\text{PGM}}\) and \(P_{\text{PBM}}\).
98 import numpy as np
99 from toqito.measurements import pretty_bad_measurement, pretty_good_measurement
100 from toqito.states import trine
101 from toqito.state_opt import state_distinguishability, state_exclusion
102
103
104 def calculate_success_prob(
105 states: list[np.ndarray],
106 probs: list[float],
107 povm_operators: list[np.ndarray],
108 ) -> float:
109 """Calculate the success probability Σ pᵢ Tr(ρᵢ Mᵢ).
110
111 This helper is robust to `states` being either state vectors or density matrices.
112 """
113 success_prob = 0
114 num_states = len(states)
115 for i in range(num_states):
116 state = states[i]
117 op = povm_operators[i]
118 # Check if input is a vector (pure state) or matrix (density matrix)
119 if state.ndim == 1 or (state.ndim == 2 and min(state.shape) == 1):
120 # It's a vector (or column/row vector)
121 state_vec = state.flatten()
122 prob_i = state_vec.conj().T @ op @ state_vec
123 else:
124 # It's a density matrix
125 prob_i = np.trace(op @ state)
126 success_prob += probs[i] * prob_i
127 return np.real(success_prob)
128
129
130 # 1. Define the states and probabilities.
131 state_vectors = trine()
132 k = len(state_vectors)
133 probs = [1 / k] * k
134
135 print(f"Analyzing k={k} trine states with uniform probability.")
136
137 # 2. Compute the optimal benchmark values.
138 p_best, _ = state_distinguishability(state_vectors, probs)
139 p_worst, _ = state_exclusion(state_vectors, probs)
140
141 print(f"\nOptimal Benchmarks:")
142 print(f" P_Best = {p_best:.4f} (Max discrimination probability)")
143 print(f" P_Worst = {p_worst:.4f} (Min discrimination probability)")
Analyzing k=3 trine states with uniform probability.
Optimal Benchmarks:
P_Best = 0.6667 (Max discrimination probability)
P_Worst = -0.0000 (Min discrimination probability)
The results for the optimal benchmarks show that the maximum possible success probability is \(2/3\), and the minimum is \(0\). The PGM is known to be optimal for the trine states, so we expect \(P_{\text{PGM}} = P_{\text{Best}}\).
150 # 3. Compute the PGM and PBM operators.
151 pgm_operators = pretty_good_measurement(state_vectors, probs)
152 pbm_operators = pretty_bad_measurement(state_vectors, probs)
153
154 # 4. Calculate PGM and PBM success probabilities.
155 p_pgm = calculate_success_prob(state_vectors, probs, pgm_operators)
156 p_pbm = calculate_success_prob(state_vectors, probs, pbm_operators)
157
158 print(f"\nHeuristic Measurements:")
159 print(f" P_PGM = {p_pgm:.4f}")
160 print(f" P_PBM = {p_pbm:.4f}")
Heuristic Measurements:
P_PGM = 0.6667
P_PBM = 0.1667
As expected, the PGM achieves the optimal value. Our calculated value for the PBM is \(1/6 \approx 0.1667\), which is a good approximation of the true worst case of \(0\).
Finally, we can verify the core relationship between these two measurements and the full performance hierarchy stated previously.
173 # 5. Verify the core relationship and the hierarchy.
174 relation_lhs = p_pgm + (k - 1) * p_pbm
175 print(f"\nVerifying P_PGM + (k-1)*P_PBM = 1:")
176 print(f" {p_pgm:.4f} + ({k - 1})*{p_pbm:.4f} = {relation_lhs:.4f} -> {np.isclose(relation_lhs, 1)}")
177
178 print("\nVerifying hierarchy (P_Best >= P_PGM >= 1/k >= P_PBM >= P_Worst):")
179 print(f" P_Best >= P_PGM: {p_best:.4f} >= {p_pgm:.4f} -> {p_best >= p_pgm or np.isclose(p_best, p_pgm)}")
180 print(f" P_PGM >= 1/k: {p_pgm:.4f} >= {1 / k:.4f} -> {p_pgm >= 1 / k or np.isclose(p_pgm, 1 / k)}")
181 print(f" 1/k >= P_PBM: {1 / k:.4f} >= {p_pbm:.4f} -> {1 / k >= p_pbm or np.isclose(1 / k, p_pbm)}")
182 print(f" P_PBM >= P_Worst: {p_pbm:.4f} >= {p_worst:.4f} -> {p_pbm >= p_worst or np.isclose(p_pbm, p_worst)}")
Verifying P_PGM + (k-1)*P_PBM = 1:
0.6667 + (2)*0.1667 = 1.0000 -> True
Verifying hierarchy (P_Best >= P_PGM >= 1/k >= P_PBM >= P_Worst):
P_Best >= P_PGM: 0.6667 >= 0.6667 -> True
P_PGM >= 1/k: 0.6667 >= 0.3333 -> True
1/k >= P_PBM: 0.3333 >= 0.1667 -> True
P_PBM >= P_Worst: 0.1667 >= -0.0000 -> True
The verifications confirm that all theoretical relationships hold true for the trine states.
Now we can move on to visualizing the performance for the more general case of random states.
Visualizing Performance on Random States¶
Figures 4 and 5 from McIrvin et. al [3] show that for many randomly generated states, the PGM and PBM probabilities cluster around the blind guessing baseline of \(1/k\). We can reproduce a similar plot.
We will generate 100 random ensembles of \(k=4\) qubit states and plot the resulting \(P_{\text{PGM}}\) and \(P_{\text{PBM}}\) values.
202 import matplotlib.pyplot as plt
203
204 from toqito.rand import random_density_matrix
205
206 # Number of random ensembles to generate.
207 num_instances = 100
208 k = 4 # Number of states in each ensemble.
209 dim = 2 # Dimension of states (qubits).
210
211 pgm_results = []
212 pbm_results = []
213
214 for i in range(num_instances):
215 # Generate a random ensemble of k density matrices.
216 rand_states = [random_density_matrix(dim, seed=(i * k) + j) for j in range(k)]
217 # Generate random prior probabilities.
218 rand_probs = np.random.dirichlet(np.ones(k))
219
220 # Calculate PGM and PBM probabilities.
221 pgm_ops = pretty_good_measurement(rand_states, rand_probs)
222 pbm_ops = pretty_bad_measurement(rand_states, rand_probs)
223
224 pgm_prob = calculate_success_prob(rand_states, rand_probs, pgm_ops)
225 pbm_prob = calculate_success_prob(rand_states, rand_probs, pbm_ops)
226 pgm_results.append(pgm_prob)
227 pbm_results.append(pbm_prob)
228
229 # Create the plot.
230 fig, ax = plt.subplots(figsize=(8, 5), dpi=100)
231 sample_indices = range(num_instances)
232 ax.scatter(sample_indices, pgm_results, alpha=0.7, label="$P_{PGM}$", c="blue", s=20)
233 ax.scatter(sample_indices, pbm_results, alpha=0.7, label="$P_{PBM}$", c="red", s=20)
234
235 # Add blind guessing line for reference.
236 blind_guess_prob = 1 / k
237 ax.axhline(
238 y=blind_guess_prob,
239 color="black",
240 linestyle="--",
241 label=f"Blind Guessing (1/k = {blind_guess_prob:.2f})",
242 )
243
244 ax.set_xlabel("Random Instance Index", fontsize=12)
245 ax.set_ylabel("Discrimination Success Probability", fontsize=12)
246 ax.set_title(f"PGM and PBM Performance for {num_instances} Random Ensembles (k={k})", fontsize=14)
247 ax.legend()
248 ax.grid(True, linestyle=":", alpha=0.6)
249 plt.tight_layout()
250 plt.show()
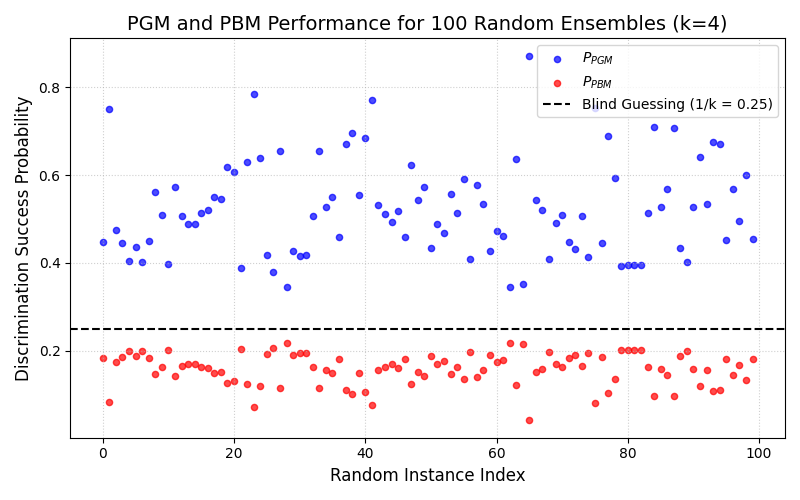
This plot clearly illustrates the theoretical bounds. Every blue dot representing \(P_{\text{PGM}}\) lies on or above the blind guessing line, and every red dot representing \(P_{\text{PBM}}\) lies on or below it. This provides strong numerical evidence for the inequalities \(P_{\text{PGM}} \ge 1/k \ge P_{\text{PBM}}\), confirming that the PGM is always a better-than-random guess and the PBM is always a worse-than-random guess for state discrimination.
References¶
Total running time of the script: (0 minutes 0.140 seconds)